Python使用Pandas的笔记
刚刚开始学 Python,这里仅仅作为自己的做笔记的地方。技能不好,请不要见怪。不会涉及到一些非常基础的,也不会涉及到很难的。只是有针对的学习,对自己有用的,数据处理方面的技能。
其实觉得Excel表格自己的Pivot Table已经很好用了。但是多学一些技能,这里记录下,自己学习Python的Pivot Table的功能,希望可以提高自己的工作效率
Pivot_table的学习笔记
import pandas as pd
#数据透视表
#pivot_table(date, value=None, index = None, Columns= Name, aggfunc="mean", fill_value=None, margins=False, dropna=Trun, margins_name ="ALL")
#date: 整张表
#values:要透视的数据,要统计的数据
#index:行索引
#columns:列索引
#aggfunc:整合函数(sum, count)
#fill_value:对空值的填充值
#margins:表示是否显示合计列,
#dropna:是否删除缺失,如果为true,就会删除有缺失值的行
#margins_name:合计列的列名
dfs=pd.read_excel(r"D:\test\newfile\solist.xlsx")
print(dfs)
print("统计各个客户的各个产品线的销售")
print(pd.pivot_table(dfs,values="SO Amount USD",index="Customer Acct", columns ="Production Line", aggfunc = "sum"))
#dfsg=pd.pivot_table(dfs,values="SO Amount USD",index="Customer Acct", columns ="Production Line", aggfunc = "sum")
#dfsg.to_excel("D:\\test\\newfile\\salesgourp1.xlsx")
#统计各个客户的各个产品线的销售,并在最后显示合计,并命名为”合计“
print(pd.pivot_table(dfs,values="SO Amount USD",index="Customer Acct", columns ="Production Line", aggfunc = "sum", margins=True, margins_name="合计"))
#统计各个客户的各个产品线的销售,并在最后显示合计,缺失值,填写为0
print(pd.pivot_table(dfs,values="SO Amount USD",index="Customer Acct", columns ="Production Line", aggfunc = "sum", margins=True, margins_name="合计", fill_value=0))
#同时统计各个客户的各个产品线的销售,同时统计美金销售数据,和外币销售数据
print(pd.pivot_table(dfs,values=["SO Amount USD","Foreign SO"],index="Customer Acct", columns ="Production Line", aggfunc = "sum", margins=True, margins_name="合计", fill_value=0))两个表格的合并
#读取excel的文件的Sheet1和Sheet2
import pandas as pd
#设置文件的位置
filePath = r"d:/test/newfile/soinfo.xlsx"
#读取Sheet1的数据
df1=pd.read_excel(filePath,sheet_name="Sheet1")
#读取Sheet2的数据
df2=pd.read_excel(filePath,sheet_name="Sheet2")
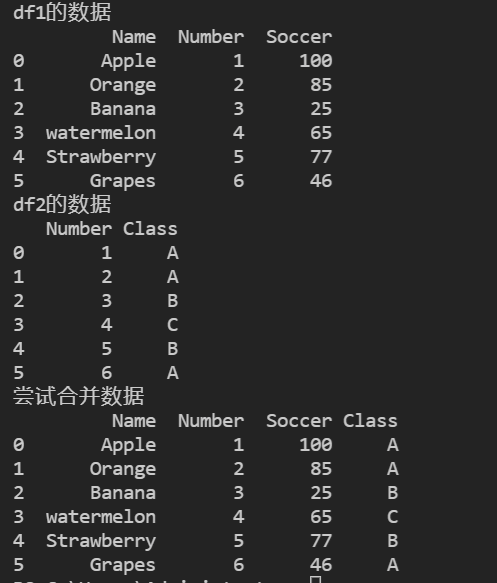
print("df1的数据")
print(df1)
print("df2的数据")
print(df2)
print("尝试合并数据")
print(pd.merge(df1,df2))然后运行的结果如下,自动会按照Number,进行合并。
结果
有时我们所得到的数据不只是一列重复还可能是多列,再试试对多列去重。
结果:
文章来源互联网,如有侵权,请联系管理员删除。邮箱:[email protected] / QQ:417803890
一、删除空值
1、删除未经处理的空值数据所在的行或列
在这种情况下我们看到的空值数据通常显示的是NaN
那么这种情况就比较好处理直接调用dropna()函数
应用:
order.dropna(axis=1)
删除过后的样子:
2、删除已用代表空值的’NA’替换过的数据
这个时候就需要写一个循环来删除数据所在行或者列(这里删的是列)
删除前先看一下数据
开始写循环
输出结果:
可以看到此时已经没有值为空的列了。
二、去重
调用去重函数pd.drop_duplicates()
应用:
首先创建一个DataFrame
(通过传递可以转换为类似系列的对象的字典来创建DataFrame)
可以看到在D列有重复的数据test和train
先试试对某一列去重(这里是D列)
# 对某一列去重
datas.drop_duplicates(['D'])
结果
有时我们所得到的数据不只是一列重复还可能是多列,再试试对多列去重。
# 对多列一起去重
datas.drop_duplicates(['A','B','C','D']) # 我们可以看到没有变化因为没有完全一样的一行
结果:


About The Author
黄大少
生活苦不苦,嚼嚼咽了。